原文はこちら。
The original entry was written by Sergii Kostenko (Java Developer).
https://kostenko.org/blog/2020/03/data-processing-with-jakarta-ee-batch-api.html
全てのエンタープライズシステムにとって、大量データの処理は課題です。Jakarta EE仕様では、Jakarta Batchを使って処理を行うという、有用なアプローチを提供しています。
Jakarta Batch [Java EEのJava Batch (JSR-352)から改称]
https://projects.eclipse.org/projects/ee4j.batch
バッチ処理は、明確なアプリケーション組織と実行モデルによって表現され、広く普及しているワークロードパターンです。バッチ処理は、ステートメントの生成、銀行の投稿、リスク評価、クレジットスコアの計算、在庫管理、ポートフォリオの最適化などのタスクに適用されており、事実上全業界で使われています。任意のビジネス部門からのバルク処理タスクは、ほぼ全てがバッチ処理の候補です。
バッチ処理には、バルク指向、非インタラクティブ、バックグラウンドでの実行という特色があります。長時間実行されることが多く、データや計算量が多く、順次または並列に実行され、アドホック、スケジューリング、オンデマンドなどのさまざまな呼び出しモデルで起動されます。
バッチアプリケーションにはロギング、チェックポイント、並列化といった共通の要件があります。バッチ処理のワークロードには共通の要件があります。特に運用制御では、バッチインスタンスの開始やバッチインスタンスとの相互作用(停止や再始動)を可能にする、という要件があります。
よくあるユースケースの一つに、異なるデータソースや形式のデータをデータベースにインポートする、というものがあります。以下で、JSONやXMLファイルのデータをデータベースにインポートするサンプルアプリケーションを設計し、どのように構造化すればよいかを見ていきましょう。
Eclipse Red Hat CodeReady Studio pluginを使い、簡単にソリューション図を設計できます。
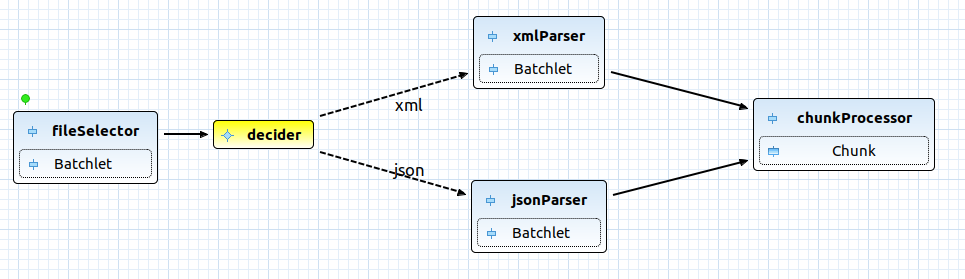
Jakarta Batch ディスクリプタ(META-INF/batch-jobs/hugeImport.xml)はこの例では以下のようになります。
<?xml version="1.0" encoding="UTF-8"?>
<job id="hugeImport" xmlns="http://xmlns.jcp.org/xml/ns/javaee" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/javaee http://xmlns.jcp.org/xml/ns/javaee/jobXML_1_0.xsd" version="1.0">
<step id="fileSelector" next="decider">
<batchlet ref="fileSelectorBatchlet">
<properties>
<property name="path" value="/tmp/files2import"/>
</properties>
</batchlet>
</step>
<decision id="decider" ref="myDecider">
<next on="xml" to="xmlParser"/>
<next on="json" to="jsonParser"/>
</decision>
<step id="xmlParser" next="chunkProcessor">
<batchlet ref="xmlParserBatchlet"/>
</step>
<step id="jsonParser" next="chunkProcessor">
<batchlet ref="jsonParserBatchlet"/>
</step>
<step id="chunkProcessor">
<chunk>
<reader ref="itemReader"/>
<processor ref="itemMockProcessor"/>
<writer ref="itemJpaWriter"/>
</chunk>
<partition>
<plan partitions="5"></plan>
</partition>
</step>
</job>
上記の各ブロックを実装し、各batchletをできる限り独立するように保つ必要があります。ご覧いただくと分かる通り、このサンプルジョブの構成要素は以下の通りです。
| fileSelector | 構成ファイルの拡張子でサポートされているファイルをbatchletが選択 |
| decider | 正しいパーサーを選択する責任のある決定者 |
| xml/jsonParser | ファイルをアイテムのリストに解析する責任を持つ、パーサーbatchlet。 |
| chunkProcessor | パフォーマンス向上のため、パーティショニングを使ってチャンクを処理するアイテム(chunkreader、時にchunkprocessorやchunkwriterなど) |
実装をはじめる前に、ステップ間で状態を共有するための有用なソリューションを設計しましょう。残念ながら、Jakarta Batch仕様ではジョブスコープのCDI beanはまだ提供されていません(JBatch実装にはありますが、仕様にはありません)。しかし、JobContext#setTransientUserData()とJobContext#getTransientUserData()を使って、現在のバッチコンテキストを取り扱うことができます。今回の例では、アイテムを持つFileとQueueを処理のために共有したいのです。
@Named
public class ImportJobContext {
@Inject
private JobContext jobContext;
private Optional<File> file = Optional.empty();
private Queue<ImportItem> items = new ConcurrentLinkedQueue<>();
public Optional<File> getFile() {
return getImportJobContext().file;
}
public void setFile(Optional<File> file) {
getImportJobContext().file = file;
}
public Queue<ImportItem> getItems() {
return getImportJobContext().items;
}
private ImportJobContext getImportJobContext() {
if (jobContext.getTransientUserData() == null) {
jobContext.setTransientUserData(this);
}
return (ImportJobContext) jobContext.getTransientUserData();
}
}
これで、カスタムのImportJobContextを注入し、型安全な除隊をbatchlet間で共有できます。まず最初にstepプロパティのPathで提示された処理対象のファイルを探します。
@Named
public class FileSelectorBatchlet extends AbstractBatchlet {
@Inject
private ImportJobContext jobContext;
@Inject
@BatchProperty
private String path;
@Override
public String process() throws Exception {
Optional<File> file = Files.walk(Paths.get(path)).filter(Files::isRegularFile).map(Path::toFile).findAny();
if (file.isPresent()) {
jobContext.setFile(file);
}
return BatchStatus.COMPLETED.name();
}
}
例えば拡張子を基にしてパーサーを選択する必要があります。Deciderは文字列としてファイル拡張子を返し、その後batch runtimeが対応するパーサーへのコントロールをbatchletに提供します。上記のXMLのバッチディスクリプタに記載の <decision id=”decider” ref=”myDecider”> を確認してください。
@Named
public class MyDecider implements Decider {
@Inject
private ImportJobContext jobContext;
@Override
public String decide(StepExecution[] ses) throws Exception {
if (!jobContext.getFile().isPresent()) {
throw new FileNotFoundException();
}
String name = jobContext.getFile().get().getName();
String extension = name.substring(name.lastIndexOf(".")+1);
return extension;
}
}
次に、ParserBatchletは、型次第でJSON-BやJAXBを使ってファイルを解析し、ImportItemオブジェクトでQueueを埋めます。パーティション間でアイテムを共有するためにConcurrentLinkedQueueを使いたいのですが、他の動作が必要な場合は、javax.batch.api.partition.PartitionMapperを独自の実装で提供することができます。
@Named
public class JsonParserBatchlet extends AbstractBatchlet {
@Inject
ImportJobContext importJobContext;
@Override
public String process() throws Exception {
List<ImportItem> items = JsonbBuilder.create().fromJson(
new FileInputStream(importJobContext.getFile().get()),
new ArrayList<ImportItem>(){}.getClass().getGenericSuperclass());
importJobContext.getItems().addAll(items);
return BatchStatus.COMPLETED.name();
}
}
その結果、ItemReaderはQueueからアイテムをプールするだけの簡単なものになります。
@Named
public class ItemReader extends AbstractItemReader {
@Inject
ImportJobContext importJobContext;
@Override
public ImportItem readItem() throws Exception {
return importJobContext.getItems().poll();
}
}
そして、永続化します。
@Named
public class ItemJpaWriter extends AbstractItemWriter {
@PersistenceContext
EntityManager entityManager;
@Override
public void writeItems(List<Object> list) throws Exception {
for (Object obj : list) {
ImportItem item = (ImportItem) obj;
entityManager.merge(item);
}
}
}
これでおしまいです。既存のコードを変更することなく、新しいパーサ、プロセッサ、ライターで簡単にアプリケーションを拡張することができるようになりました。Jaarta Batchディスクリプタに新しいフロー(もしくは更新した既存のフロー)を記述するだけです。
もちろん、Jakarta Batch仕様は、このエントリ扱っているよりもはるかに多くの有用な機能を提供しています(チェックポイント、例外処理、リスナー、フロー制御、失敗したジョブの再起動など)が、この例だけでも、いかにシンプルで、強力かつよく構造化されていることがわかるかと思います。
注意
Wildfly Application Serverではbatch-jberetサブシステムを使ってJakarta Batch仕様を実装していますが、デフォルトでは、最大スレッド数は10です。
<subsystem xmlns="urn:jboss:domain:batch-jberet:2.0">
...
<thread-pool name="batch">
<max-threads count="10"/>
<keepalive-time time="30" unit="seconds"/>
</thread-pool>
</subsystem>
それゆえ、Batch runtimeを集中的に使用しようと考えているなら、このパラメータを増やしてください。
/subsystem=batch-jberet/thread-pool=batch/:write-attribute(name=max-threads, value=100)
ご紹介したサンプルアプリのソースコードは以下のGitHubリポジトリからどうぞ。
batch-processing-examples
https://github.com/kostenkoserg/ee-batch-processing-examples
