原文はこちら。
The original entry was written by Richard Startin.
https://richardstartin.github.io/posts/vectorised-byte-operations
JDK13 以降、byte[]での多くの演算がC2でベクトル化できるようになりました。これらの改善は、IntelがC2のAVX+命令の使用を改善するために行った長年の貢献に由来しており、x86で実行される多くのJavaプログラムを高速化する可能性があります。これが理想的な状況でどれだけ大きな影響を与えることができるかを調べるだけでなく、Unsafeを使用する古い、きちんと理解するのが難しい代替案と単純なルーチンを比較したくて仕方ありません。
Enhance auto vectorization for x86
https://bugs.openjdk.java.net/browse/JDK-8222074
このエントリでは、論理右または符号なし右シフト(>>>)と符号を保持する算術右シフト(>>)に焦点を当てます。これらの演算は典型的なJavaプログラムでは必ずしもあまり一般的とはいえませんが、最初の演算は圧縮アルゴリズムで、2番目の演算は低精度の符号付き演算で見られる可能性があります。これらの演算が文字列処理に有用であることは想像に難くありませんし、符号なしシフトはvector bit count algorithmで byte (octet, 8 bits) から nibble (4bit) を抽出するために使用されます。
これらのベンチマークをノートPCで実行しました。マシンはCPUはmobile SkyIake、AVX2を搭載しており、OSはUbuntu 18です。これは必ずしもベンチマーク実行に当たって最適な環境とはいえませんが、バージョン間の大まかな違いを把握する上では十分ですし、診断プロファイラ(diagnostic profiler)へのアクセスもできます。今回はJDK 11とJDK 13早期アクセスビルドで比較しました。
まずは論理右シフトからです。これは符号ビットも含め全てのビットをゼロにシフトするというものです。
@Benchmark
public void shiftLogical(ByteShiftState state, Blackhole bh) {
byte[] data = state.data;
byte[] target = state.target;
int shift = state.shift;
shiftLogical(data, target, shift);
bh.consume(target);
}
void shiftLogical(byte[] data, byte[] target, int shift) {
for (int i = 0; i < data.length; ++i) {
target[i] = (byte)((data[i] & 0xFF) >>> shift);
}
}
ブラックホール(benchmark smell)がイテレーション内で生成される個別の値を消費しない理由に疑問を持つ人もいるかと思いますが、それはベンチマークのポイントがどのループで最適化が発生するかを見るためだからです。
What’s Wrong With My Benchmark Results? Studying Bad Practices in JMH Benchmarks
https://www.researchgate.net/publication/333825812_What’s_Wrong_With_My_Benchmark_Results_Studying_Bad_Practices_in_JMH_Benchmarks
マスクは何をしているのでしょうか。マスクがない場合、この演算には全く意味がないのです。仕様上、シフト前にbyteはint(符号拡張付き)にキャストされ、シフト後にbyteに戻されるため、その結果負になる可能性があるからです。Javaでは常にこのように動作してきましたが、これが常に価値があるのか、という下位互換性についての疑問を投げかけています。既存のコードにマスクされていないシフトが含まれている場合、それは本当に作者の意図したものなのでしょうか。いずれにしても、Intel がこのような無茶苦茶な演算をベクトル化して時間を無駄にしなかったと願っていますので、JDK13 でベンチマークのスループットが大幅に向上したマスク付きシフトだけを見ることにします。
以下は、shiftLogical のスループットを JDK11 および JDK13 と比較した棒グラフ(生データつき)です。サイズの選択は、ベクトル幅の倍数を選択することで、ポストループの効果を捕捉することを目的としています(数値が大きいほどよいです)。
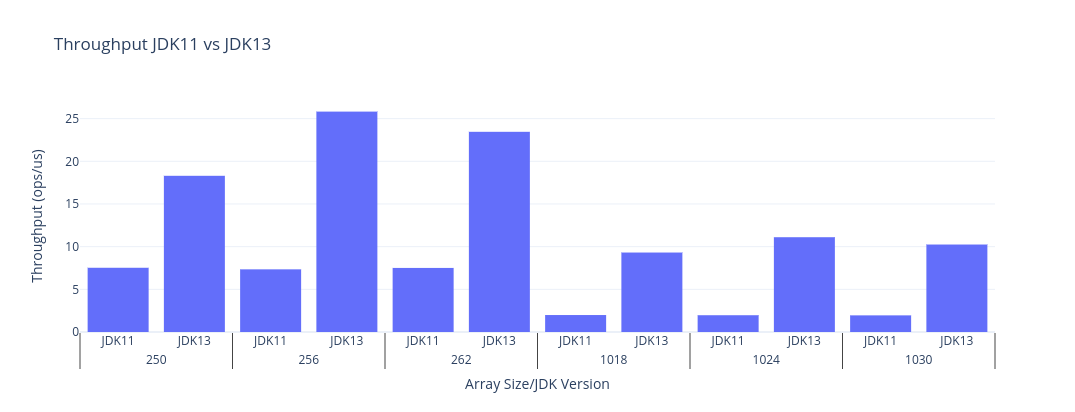
| JDK | Benchmark | Mode | Threads | Samples | Score | Score Error (99.9%) | Unit | Param: shift | Param: size |
|---|---|---|---|---|---|---|---|---|---|
| 13 | shiftLogical | thrpt | 1 | 5 | 18.191279 | 0.281667 | ops/us | 0 | 250 |
| 13 | shiftLogical | thrpt | 1 | 5 | 20.274241 | 0.482750 | ops/us | 0 | 256 |
| 13 | shiftLogical | thrpt | 1 | 5 | 23.666673 | 2.447062 | ops/us | 0 | 262 |
| 13 | shiftLogical | thrpt | 1 | 5 | 9.315800 | 0.289419 | ops/us | 0 | 1018 |
| 13 | shiftLogical | thrpt | 1 | 5 | 9.706462 | 0.275737 | ops/us | 0 | 1024 |
| 13 | shiftLogical | thrpt | 1 | 5 | 10.367262 | 0.183024 | ops/us | 0 | 1030 |
| 13 | shiftLogical | thrpt | 1 | 5 | 18.301114 | 1.095593 | ops/us | 1 | 250 |
| 13 | shiftLogical | thrpt | 1 | 5 | 25.823625 | 0.463037 | ops/us | 1 | 256 |
| 13 | shiftLogical | thrpt | 1 | 5 | 23.456042 | 0.533061 | ops/us | 1 | 262 |
| 13 | shiftLogical | thrpt | 1 | 5 | 9.311597 | 0.117147 | ops/us | 1 | 1018 |
| 13 | shiftLogical | thrpt | 1 | 5 | 11.106354 | 1.126994 | ops/us | 1 | 1024 |
| 13 | shiftLogical | thrpt | 1 | 5 | 10.250077 | 0.242414 | ops/us | 1 | 1030 |
| 13 | shiftLogical | thrpt | 1 | 5 | 18.609886 | 1.933992 | ops/us | 7 | 250 |
| 13 | shiftLogical | thrpt | 1 | 5 | 25.242200 | 0.667229 | ops/us | 7 | 256 |
| 13 | shiftLogical | thrpt | 1 | 5 | 23.111450 | 0.521140 | ops/us | 7 | 262 |
| 13 | shiftLogical | thrpt | 1 | 5 | 9.270754 | 0.563155 | ops/us | 7 | 1018 |
| 13 | shiftLogical | thrpt | 1 | 5 | 9.891347 | 0.052645 | ops/us | 7 | 1024 |
| 13 | shiftLogical | thrpt | 1 | 5 | 10.390528 | 0.225605 | ops/us | 7 | 1030 |
| 13 | shiftLogical | thrpt | 1 | 5 | 18.491362 | 0.388118 | ops/us | 8 | 250 |
| 13 | shiftLogical | thrpt | 1 | 5 | 25.319509 | 0.176510 | ops/us | 8 | 256 |
| 13 | shiftLogical | thrpt | 1 | 5 | 22.932418 | 0.470137 | ops/us | 8 | 262 |
| 13 | shiftLogical | thrpt | 1 | 5 | 9.363212 | 0.024503 | ops/us | 8 | 1018 |
| 13 | shiftLogical | thrpt | 1 | 5 | 10.879806 | 0.108640 | ops/us | 8 | 1024 |
| 13 | shiftLogical | thrpt | 1 | 5 | 10.552629 | 0.497255 | ops/us | 8 | 1030 |
| 11 | shiftLogical | thrpt | 1 | 5 | 7.519700 | 0.107267 | ops/us | 0 | 250 |
| 11 | shiftLogical | thrpt | 1 | 5 | 7.464531 | 0.308817 | ops/us | 0 | 256 |
| 11 | shiftLogical | thrpt | 1 | 5 | 7.473977 | 0.122781 | ops/us | 0 | 262 |
| 11 | shiftLogical | thrpt | 1 | 5 | 1.963351 | 0.061825 | ops/us | 0 | 1018 |
| 11 | shiftLogical | thrpt | 1 | 5 | 1.965883 | 0.139291 | ops/us | 0 | 1024 |
| 11 | shiftLogical | thrpt | 1 | 5 | 2.008736 | 0.188627 | ops/us | 0 | 1030 |
| 11 | shiftLogical | thrpt | 1 | 5 | 7.525109 | 0.047179 | ops/us | 1 | 250 |
| 11 | shiftLogical | thrpt | 1 | 5 | 7.341725 | 0.183424 | ops/us | 1 | 256 |
| 11 | shiftLogical | thrpt | 1 | 5 | 7.506334 | 0.127763 | ops/us | 1 | 262 |
| 11 | shiftLogical | thrpt | 1 | 5 | 1.987959 | 0.009052 | ops/us | 1 | 1018 |
| 11 | shiftLogical | thrpt | 1 | 5 | 1.966036 | 0.095510 | ops/us | 1 | 1024 |
| 11 | shiftLogical | thrpt | 1 | 5 | 1.949898 | 0.074998 | ops/us | 1 | 1030 |
| 11 | shiftLogical | thrpt | 1 | 5 | 7.571452 | 0.133089 | ops/us | 7 | 250 |
| 11 | shiftLogical | thrpt | 1 | 5 | 7.422129 | 0.542094 | ops/us | 7 | 256 |
| 11 | shiftLogical | thrpt | 1 | 5 | 7.429609 | 0.154287 | ops/us | 7 | 262 |
| 11 | shiftLogical | thrpt | 1 | 5 | 1.965460 | 0.076335 | ops/us | 7 | 1018 |
| 11 | shiftLogical | thrpt | 1 | 5 | 1.969899 | 0.096004 | ops/us | 7 | 1024 |
| 11 | shiftLogical | thrpt | 1 | 5 | 1.983031 | 0.016293 | ops/us | 7 | 1030 |
| 11 | shiftLogical | thrpt | 1 | 5 | 7.531941 | 0.139384 | ops/us | 8 | 250 |
| 11 | shiftLogical | thrpt | 1 | 5 | 7.367593 | 0.215386 | ops/us | 8 | 256 |
| 11 | shiftLogical | thrpt | 1 | 5 | 7.456574 | 0.160798 | ops/us | 8 | 262 |
| 11 | shiftLogical | thrpt | 1 | 5 | 2.027801 | 0.066184 | ops/us | 8 | 1018 |
| 11 | shiftLogical | thrpt | 1 | 5 | 2.096556 | 0.005543 | ops/us | 8 | 1024 |
| 11 | shiftLogical | thrpt | 1 | 5 | 1.948405 | 0.007283 | ops/us | 8 | 1030 |
マイナーJDKリリースで大幅に改善されています。おそらくは1年ごとに2バージョンのJDKをリリースすることが結局のところよいのでしょうか。以下はperfasmのJDK13ベクトル化ループ部分です(vpsrlw を参照)。
0.29% ││││ │ 0x00007f0090365bf3: vmovdqu 0x10(%rdi,%r9,1),%ymm2
0.86% 0.58% ││││ │ 0x00007f0090365bfa: vextracti128 $0x1,%ymm2,%xmm4
0.57% 0.29% ││││ │ 0x00007f0090365c00: vpmovsxbw %xmm4,%ymm4
0.19% 1.16% ││││ │ 0x00007f0090365c05: vpmovsxbw %xmm2,%ymm5
0.19% 0.19% ││││ │ 0x00007f0090365c0a: vpsrlw %xmm3,%ymm4,%ymm4
2.30% 2.42% ││││ │ 0x00007f0090365c0e: vpsrlw %xmm3,%ymm5,%ymm5
1.25% 1.16% ││││ │ 0x00007f0090365c12: vpand -0x7ab00da(%rip),%ymm4,%ymm4 # Stub::vector_short_to_byte_mask
││││ │ ; {external_word}
1.15% 1.55% ││││ │ 0x00007f0090365c1a: vpand -0x7ab00e2(%rip),%ymm5,%ymm5 # Stub::vector_short_to_byte_mask
││││ │ ; {external_word}
0.96% 0.87% ││││ │ 0x00007f0090365c22: vpackuswb %ymm4,%ymm5,%ymm5
1.34% 0.58% ││││ │ 0x00007f0090365c26: vpermq $0xd8,%ymm5,%ymm5
3.35% 4.95% ││││ │ 0x00007f0090365c2c: vmovdqu %ymm5,0x10(%r11,%r9,1)
2.20% 1.75% ││││ │ 0x00007f0090365c33: vmovdqu 0x30(%rdi,%r9,1),%ymm2
0.10% ││││ │ 0x00007f0090365c3a: vextracti128 $0x1,%ymm2,%xmm4
0.96% 0.58% ││││ │ 0x00007f0090365c40: vpmovsxbw %xmm4,%ymm4
││││ │ 0x00007f0090365c45: vpmovsxbw %xmm2,%ymm5
1.53% 1.55% ││││ │ 0x00007f0090365c4a: vpsrlw %xmm3,%ymm4,%ymm4
1.05% 1.16% ││││ │ 0x00007f0090365c4e: vpsrlw %xmm3,%ymm5,%ymm5
1.72% 1.45% ││││ │ 0x00007f0090365c52: vpand -0x7ab011a(%rip),%ymm4,%ymm4 # Stub::vector_short_to_byte_mask
││││ │ ; {external_word}
0.10% ││││ │ 0x00007f0090365c5a: vpand -0x7ab0122(%rip),%ymm5,%ymm5 # Stub::vector_short_to_byte_mask
││││ │ ; {external_word}
1.05% 0.78% ││││ │ 0x00007f0090365c62: vpackuswb %ymm4,%ymm5,%ymm5
0.10% ││││ │ 0x00007f0090365c66: vpermq $0xd8,%ymm5,%ymm5
4.02% 3.69% ││││ │ 0x00007f0090365c6c: vmovdqu %ymm5,0x30(%r11,%r9,1)
以下は、ずっと低速なJDK 11のスカラーループです(shrを参照)。
1.66% ││ 0x00007f30c4758943: movzbl 0x10(%r8,%rbp,1),%r11d
0.09% 0.09% ││ 0x00007f30c4758949: shr %cl,%r11d
1.29% 2.34% ││ 0x00007f30c475894c: mov %r11b,0x10(%rdi,%rbp,1)
0.18% ││ 0x00007f30c4758951: movzbl 0x11(%r8,%rbp,1),%r11d
0.09% ││ 0x00007f30c4758957: shr %cl,%r11d
2.68% ││ 0x00007f30c475895a: mov %r11b,0x11(%rdi,%rbp,1)
以前このようなことをする必要があって、妥当な効率性を必要とした場合、Unsafeを使用するSIMD Within A Register (SWAR) アプローチを採用したことがあるかもしれません。C言語のような低レベルの言語では、キャスティングによって異なる幅の整数型間で曖昧にすることが可能で、その際パフォーマンスのオーバーヘッドはありません。Javaでは、8個の要素を持つbyte配列からlongを組み立てるのは非常にコストがかかりますが、Unsafeを使えばC言語のプログラマーと同じようなアプローチが可能です。以下のコードは、shiftLogicalと同じことを実現していますが、一度に8バイトに対して作用しています。最初にシフトを適用し、続いてマスクを適用してbyteの各々の上位端へのビットの流れを取り除きます。(0と8を含む)9シフトしかできないため、マスクをルックアップテーブルに書き込むことができますが、その際は16進ではなくバイナリでルックアップテーブルに書き込まれます。
public static final long[] MASKS = new long[]{
0b1111111111111111111111111111111111111111111111111111111111111111L,
0b0111111101111111011111110111111101111111011111110111111101111111L,
0b0011111100111111001111110011111100111111001111110011111100111111L,
0b0001111100011111000111110001111100011111000111110001111100011111L,
0b0000111100001111000011110000111100001111000011110000111100001111L,
0b0000011100000111000001110000011100000111000001110000011100000111L,
0b0000001100000011000000110000001100000011000000110000001100000011L,
0b0000000100000001000000010000000100000001000000010000000100000001L,
0b0000000000000000000000000000000000000000000000000000000000000000L
};
以下はUnsafeを使ったSWARの実装です。
@Benchmark
public void shiftLogicalUnsafe(ByteShiftState state, Blackhole bh) {
byte[] data = state.data;
byte[] target = state.target;
int shift = state.shift;
shiftLogicalUnsafe(data, target, shift);
bh.consume(target);
}
void shiftLogicalUnsafe(byte[] data, byte[] target, int shift) {
long mask = MASKS[shift];
int i = 0;
for (; i + 7 < data.length; i += 8) {
long word = UNSAFE.getLong(data, BYTE_ARRAY_OFFSET + i);
word >>>= shift;
word &= mask;
UNSAFE.putLong(target, BYTE_ARRAY_OFFSET + i, word);
}
for (; i < data.length; ++i) {
target[i] = (byte)((data[i] & 0xFF) >>> shift);
}
}
この実装はほとんど労力をしないため、JDK11のシンプルなアプローチよりもはるかに優れています。JDK13では、単純なコードは高度に最適化されているため、ギャップは事実上ゼロになっています。そのため、より長い配列で一層高速になりますが、このベンチマークでは、短い配列でもなおまさっています。
以下のグラフはベンチマーク結果を示しています。ここで赤色の系列は各JDKバージョンと配列サイズに対して測定されたスループット(高いほどよい)であり、青色の系列は各ケースでUnsafeを使うことによって得られるアドバンテージです。素データは下に記載してあります。
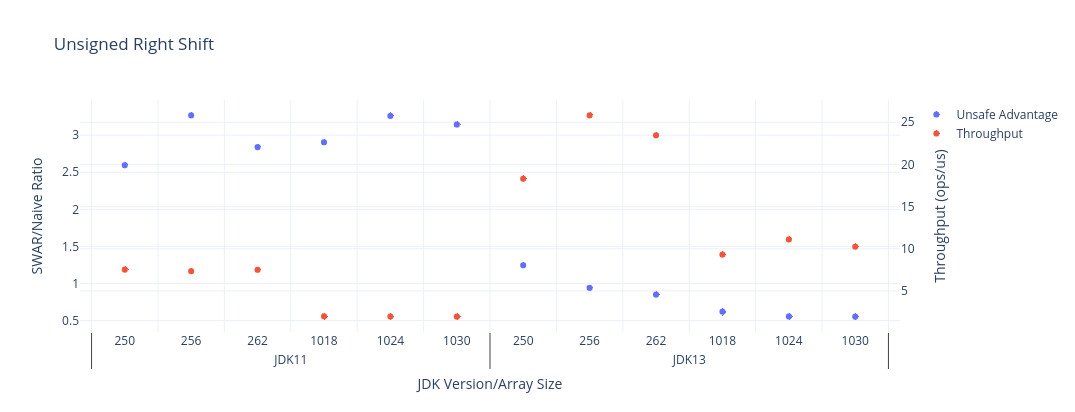
| JDK | Benchmark | Mode | Threads | Samples | Score | Score Error (99.9%) | Unit | Param: shift | Param: size |
|---|---|---|---|---|---|---|---|---|---|
| 13 | shiftLogical | thrpt | 1 | 5 | 18.191279 | 0.281667 | ops/us | 0 | 250 |
| 13 | shiftLogical | thrpt | 1 | 5 | 20.274241 | 0.482750 | ops/us | 0 | 256 |
| 13 | shiftLogical | thrpt | 1 | 5 | 23.666673 | 2.447062 | ops/us | 0 | 262 |
| 13 | shiftLogical | thrpt | 1 | 5 | 9.315800 | 0.289419 | ops/us | 0 | 1018 |
| 13 | shiftLogical | thrpt | 1 | 5 | 9.706462 | 0.275737 | ops/us | 0 | 1024 |
| 13 | shiftLogical | thrpt | 1 | 5 | 10.367262 | 0.183024 | ops/us | 0 | 1030 |
| 13 | shiftLogical | thrpt | 1 | 5 | 18.301114 | 1.095593 | ops/us | 1 | 250 |
| 13 | shiftLogical | thrpt | 1 | 5 | 25.823625 | 0.463037 | ops/us | 1 | 256 |
| 13 | shiftLogical | thrpt | 1 | 5 | 23.456042 | 0.533061 | ops/us | 1 | 262 |
| 13 | shiftLogical | thrpt | 1 | 5 | 9.311597 | 0.117147 | ops/us | 1 | 1018 |
| 13 | shiftLogical | thrpt | 1 | 5 | 11.106354 | 1.126994 | ops/us | 1 | 1024 |
| 13 | shiftLogical | thrpt | 1 | 5 | 10.250077 | 0.242414 | ops/us | 1 | 1030 |
| 13 | shiftLogical | thrpt | 1 | 5 | 18.609886 | 1.933992 | ops/us | 7 | 250 |
| 13 | shiftLogical | thrpt | 1 | 5 | 25.242200 | 0.667229 | ops/us | 7 | 256 |
| 13 | shiftLogical | thrpt | 1 | 5 | 23.111450 | 0.521140 | ops/us | 7 | 262 |
| 13 | shiftLogical | thrpt | 1 | 5 | 9.270754 | 0.563155 | ops/us | 7 | 1018 |
| 13 | shiftLogical | thrpt | 1 | 5 | 9.891347 | 0.052645 | ops/us | 7 | 1024 |
| 13 | shiftLogical | thrpt | 1 | 5 | 10.390528 | 0.225605 | ops/us | 7 | 1030 |
| 13 | shiftLogical | thrpt | 1 | 5 | 18.491362 | 0.388118 | ops/us | 8 | 250 |
| 13 | shiftLogical | thrpt | 1 | 5 | 25.319509 | 0.176510 | ops/us | 8 | 256 |
| 13 | shiftLogical | thrpt | 1 | 5 | 22.932418 | 0.470137 | ops/us | 8 | 262 |
| 13 | shiftLogical | thrpt | 1 | 5 | 9.363212 | 0.024503 | ops/us | 8 | 1018 |
| 13 | shiftLogical | thrpt | 1 | 5 | 10.879806 | 0.108640 | ops/us | 8 | 1024 |
| 13 | shiftLogical | thrpt | 1 | 5 | 10.552629 | 0.497255 | ops/us | 8 | 1030 |
| 13 | shiftLogicalUnsafe | thrpt | 1 | 5 | 22.077246 | 1.081037 | ops/us | 0 | 250 |
| 13 | shiftLogicalUnsafe | thrpt | 1 | 5 | 23.892896 | 0.443875 | ops/us | 0 | 256 |
| 13 | shiftLogicalUnsafe | thrpt | 1 | 5 | 20.037400 | 0.197346 | ops/us | 0 | 262 |
| 13 | shiftLogicalUnsafe | thrpt | 1 | 5 | 5.773376 | 0.094510 | ops/us | 0 | 1018 |
| 13 | shiftLogicalUnsafe | thrpt | 1 | 5 | 6.165100 | 0.164495 | ops/us | 0 | 1024 |
| 13 | shiftLogicalUnsafe | thrpt | 1 | 5 | 5.635749 | 0.096095 | ops/us | 0 | 1030 |
| 13 | shiftLogicalUnsafe | thrpt | 1 | 5 | 22.803000 | 2.328542 | ops/us | 1 | 250 |
| 13 | shiftLogicalUnsafe | thrpt | 1 | 5 | 24.306697 | 0.415944 | ops/us | 1 | 256 |
| 13 | shiftLogicalUnsafe | thrpt | 1 | 5 | 19.932682 | 0.397168 | ops/us | 1 | 262 |
| 13 | shiftLogicalUnsafe | thrpt | 1 | 5 | 5.783751 | 0.070052 | ops/us | 1 | 1018 |
| 13 | shiftLogicalUnsafe | thrpt | 1 | 5 | 6.176860 | 0.087320 | ops/us | 1 | 1024 |
| 13 | shiftLogicalUnsafe | thrpt | 1 | 5 | 5.672405 | 0.309824 | ops/us | 1 | 1030 |
| 13 | shiftLogicalUnsafe | thrpt | 1 | 5 | 22.398695 | 6.500715 | ops/us | 7 | 250 |
| 13 | shiftLogicalUnsafe | thrpt | 1 | 5 | 24.016902 | 1.427922 | ops/us | 7 | 256 |
| 13 | shiftLogicalUnsafe | thrpt | 1 | 5 | 19.839427 | 0.253299 | ops/us | 7 | 262 |
| 13 | shiftLogicalUnsafe | thrpt | 1 | 5 | 5.651263 | 0.285734 | ops/us | 7 | 1018 |
| 13 | shiftLogicalUnsafe | thrpt | 1 | 5 | 6.021468 | 0.372450 | ops/us | 7 | 1024 |
| 13 | shiftLogicalUnsafe | thrpt | 1 | 5 | 5.660459 | 0.332135 | ops/us | 7 | 1030 |
| 13 | shiftLogicalUnsafe | thrpt | 1 | 5 | 21.743651 | 0.919695 | ops/us | 8 | 250 |
| 13 | shiftLogicalUnsafe | thrpt | 1 | 5 | 24.134360 | 0.649705 | ops/us | 8 | 256 |
| 13 | shiftLogicalUnsafe | thrpt | 1 | 5 | 19.844468 | 0.083193 | ops/us | 8 | 262 |
| 13 | shiftLogicalUnsafe | thrpt | 1 | 5 | 5.760863 | 0.832170 | ops/us | 8 | 1018 |
| 13 | shiftLogicalUnsafe | thrpt | 1 | 5 | 6.147889 | 0.058199 | ops/us | 8 | 1024 |
| 13 | shiftLogicalUnsafe | thrpt | 1 | 5 | 5.615899 | 0.098102 | ops/us | 8 | 1030 |
ベンチマークをより良いマシン上で実行すれば異なる結果になるかもしれませんが、AVX-512チップには当てはまらないでしょうし、自動ベクトル化の利点にも賭けています。
算術シフトについてどうでしょう。算術シフトの場合、最も重要なビットをセットする際には常に1を、そうでないときにはゼロで埋めて符号を保持するため、符号なしシフトではなくマスキングなしのbyte配列に適用した方が意味があります。この簡単なコードは、JDK13の自動ベクトル化の対象となっているため、ほほぼ同じです。
@Benchmark
public void shiftArithmetic(ByteShiftState state, Blackhole bh) {
byte[] data = state.data;
byte[] target = state.target;
int shift = state.shift;
shiftArithmetic(data, target, shift);
bh.consume(target);
}
void shiftArithmetic(byte[] data, byte[] target, int shift) {
for (int i = 0; i < data.length; ++i) {
target[i] = (byte)(data[i] >> shift);
}
}
この2の補数演算をSWARでエミュレートするのは非常に難しいですが、特に0x80と0x00を等価と考えれば、似たようなことが可能です(例えば算術計算の場合)。
- まず、符号ビット(8ビットごと)をキャプチャして保存する
- 続いて、符号ビットをオフにして符号ビットが右シフトしないようにする
- シフト
- その後、各バイトの上位ビットにシフトされた任意のビットをマスクする
- 最後に、符号ビットを戻す
実際のところ、これではbyteをゼロにシフトした場合の正しいビット単位の結果は得られませんが、符号付き算術の場合は問題ありません。
@Benchmark
public void shiftArithmeticUnsafe(ByteShiftState state, Blackhole bh) {
byte[] data = state.data;
byte[] target = state.target;
int shift = state.shift;
shiftArithmeticUnsafe(data, target, shift);
bh.consume(target);
}
void shiftArithmeticUnsafe(byte[] data, byte[] target, int shift) {
long mask = MASKS[shift];
int i = 0;
for (; i + 7 < data.length; i += 8) {
long word = UNSAFE.getLong(data, BYTE_ARRAY_OFFSET + i);
long signs = word & SIGN_BITS;
word &= ~SIGN_BITS;
word >>>= shift;
word &= mask;
word |= signs;
UNSAFE.putLong(target, BYTE_ARRAY_OFFSET + i, word);
}
for (; i < data.length; ++i) {
target[i] = (byte)(data[i] >> shift);
}
}
これはかなり複雑かつスループットに影響を与えますが、JDK11では間違いなく価値があります。幸いなことに、単純なコードはJDK13でより高速なので、試してみる必要はありません。
繰り返しになりますが、下の赤色の系列は、各JDKバージョンと配列サイズに対するスループットの測定値(高いほど良い)で、青色の系列は、それぞれのケースでUnsafeを使用することで得られる利点です。グラフの下に生データが表示されています。
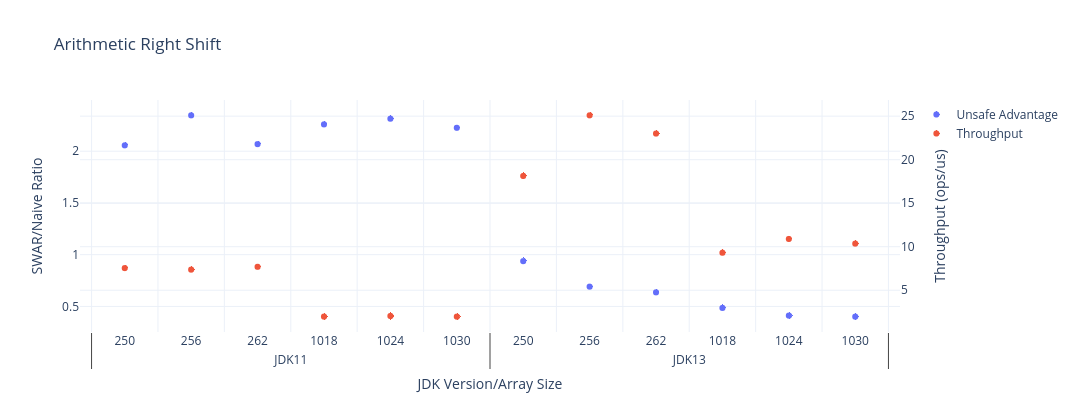
以下は前のグラフと同じ幅で取得したデータを使って、shiftArithmeticをJDK11とJDK13で比較した棒グラフです。
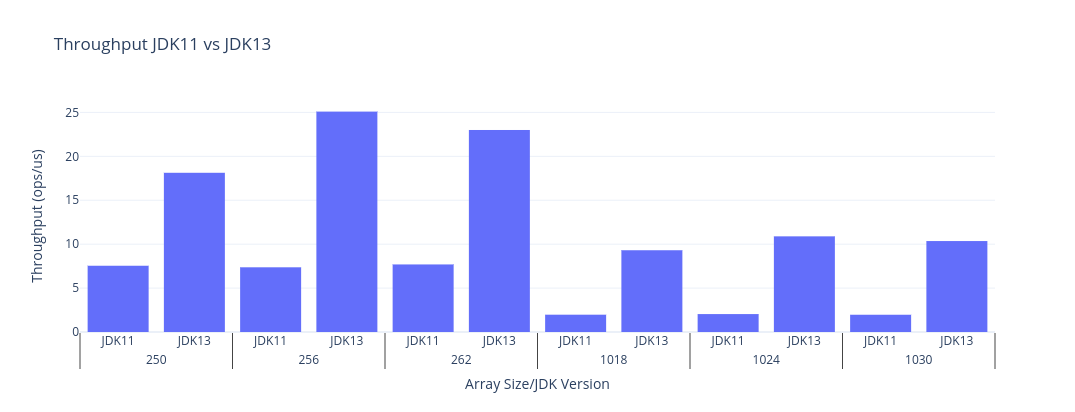
| JDK | Benchmark | Mode | Threads | Samples | Score | Score Error (99.9%) | Unit | Param: shift | Param: size |
|---|---|---|---|---|---|---|---|---|---|
| 11 | shiftArithmetic | thrpt | 1 | 5 | 7.557823 | 0.065235 | ops/us | 0 | 250 |
| 11 | shiftArithmetic | thrpt | 1 | 5 | 7.256637 | 0.981208 | ops/us | 0 | 256 |
| 11 | shiftArithmetic | thrpt | 1 | 5 | 7.476520 | 0.035784 | ops/us | 0 | 262 |
| 11 | shiftArithmetic | thrpt | 1 | 5 | 1.976303 | 0.026156 | ops/us | 0 | 1018 |
| 11 | shiftArithmetic | thrpt | 1 | 5 | 1.958443 | 0.023188 | ops/us | 0 | 1024 |
| 11 | shiftArithmetic | thrpt | 1 | 5 | 1.966061 | 0.026168 | ops/us | 0 | 1030 |
| 11 | shiftArithmetic | thrpt | 1 | 5 | 7.543830 | 0.109140 | ops/us | 1 | 250 |
| 11 | shiftArithmetic | thrpt | 1 | 5 | 7.366226 | 0.046778 | ops/us | 1 | 256 |
| 11 | shiftArithmetic | thrpt | 1 | 5 | 7.691954 | 0.380654 | ops/us | 1 | 262 |
| 11 | shiftArithmetic | thrpt | 1 | 5 | 1.970481 | 0.042620 | ops/us | 1 | 1018 |
| 11 | shiftArithmetic | thrpt | 1 | 5 | 2.039890 | 0.120633 | ops/us | 1 | 1024 |
| 11 | shiftArithmetic | thrpt | 1 | 5 | 1.965348 | 0.010959 | ops/us | 1 | 1030 |
| 11 | shiftArithmetic | thrpt | 1 | 5 | 7.525700 | 0.216891 | ops/us | 7 | 250 |
| 11 | shiftArithmetic | thrpt | 1 | 5 | 7.347915 | 0.071271 | ops/us | 7 | 256 |
| 11 | shiftArithmetic | thrpt | 1 | 5 | 7.488201 | 0.037903 | ops/us | 7 | 262 |
| 11 | shiftArithmetic | thrpt | 1 | 5 | 2.009900 | 0.032639 | ops/us | 7 | 1018 |
| 11 | shiftArithmetic | thrpt | 1 | 5 | 1.958373 | 0.044689 | ops/us | 7 | 1024 |
| 11 | shiftArithmetic | thrpt | 1 | 5 | 2.044459 | 0.216456 | ops/us | 7 | 1030 |
| 11 | shiftArithmetic | thrpt | 1 | 5 | 7.536948 | 0.124611 | ops/us | 8 | 250 |
| 11 | shiftArithmetic | thrpt | 1 | 5 | 7.336482 | 0.059378 | ops/us | 8 | 256 |
| 11 | shiftArithmetic | thrpt | 1 | 5 | 7.470758 | 0.151656 | ops/us | 8 | 262 |
| 11 | shiftArithmetic | thrpt | 1 | 5 | 1.972328 | 0.026727 | ops/us | 8 | 1018 |
| 11 | shiftArithmetic | thrpt | 1 | 5 | 2.027925 | 0.170155 | ops/us | 8 | 1024 |
| 11 | shiftArithmetic | thrpt | 1 | 5 | 1.967295 | 0.025890 | ops/us | 8 | 1030 |
| 13 | shiftArithmetic | thrpt | 1 | 5 | 18.247787 | 0.177523 | ops/us | 0 | 250 |
| 13 | shiftArithmetic | thrpt | 1 | 5 | 25.189287 | 0.083362 | ops/us | 0 | 256 |
| 13 | shiftArithmetic | thrpt | 1 | 5 | 23.878128 | 1.486587 | ops/us | 0 | 262 |
| 13 | shiftArithmetic | thrpt | 1 | 5 | 9.286776 | 0.169307 | ops/us | 0 | 1018 |
| 13 | shiftArithmetic | thrpt | 1 | 5 | 10.914047 | 0.060050 | ops/us | 0 | 1024 |
| 13 | shiftArithmetic | thrpt | 1 | 5 | 10.564764 | 0.303730 | ops/us | 0 | 1030 |
| 13 | shiftArithmetic | thrpt | 1 | 5 | 18.126012 | 0.497112 | ops/us | 1 | 250 |
| 13 | shiftArithmetic | thrpt | 1 | 5 | 25.092744 | 0.685261 | ops/us | 1 | 256 |
| 13 | shiftArithmetic | thrpt | 1 | 5 | 22.999389 | 0.303475 | ops/us | 1 | 262 |
| 13 | shiftArithmetic | thrpt | 1 | 5 | 9.308794 | 0.242943 | ops/us | 1 | 1018 |
| 13 | shiftArithmetic | thrpt | 1 | 5 | 10.889987 | 0.201891 | ops/us | 1 | 1024 |
| 13 | shiftArithmetic | thrpt | 1 | 5 | 10.354830 | 0.204797 | ops/us | 1 | 1030 |
| 13 | shiftArithmetic | thrpt | 1 | 5 | 18.104929 | 0.833391 | ops/us | 7 | 250 |
| 13 | shiftArithmetic | thrpt | 1 | 5 | 25.525225 | 1.058005 | ops/us | 7 | 256 |
| 13 | shiftArithmetic | thrpt | 1 | 5 | 22.890170 | 0.457192 | ops/us | 7 | 262 |
| 13 | shiftArithmetic | thrpt | 1 | 5 | 9.324288 | 0.196076 | ops/us | 7 | 1018 |
| 13 | shiftArithmetic | thrpt | 1 | 5 | 10.891533 | 0.082364 | ops/us | 7 | 1024 |
| 13 | shiftArithmetic | thrpt | 1 | 5 | 10.571187 | 0.222624 | ops/us | 7 | 1030 |
| 13 | shiftArithmetic | thrpt | 1 | 5 | 18.175808 | 0.452371 | ops/us | 8 | 250 |
| 13 | shiftArithmetic | thrpt | 1 | 5 | 25.245452 | 0.396196 | ops/us | 8 | 256 |
| 13 | shiftArithmetic | thrpt | 1 | 5 | 23.109097 | 0.061468 | ops/us | 8 | 262 |
| 13 | shiftArithmetic | thrpt | 1 | 5 | 9.284711 | 0.256823 | ops/us | 8 | 1018 |
| 13 | shiftArithmetic | thrpt | 1 | 5 | 10.877813 | 0.105014 | ops/us | 8 | 1024 |
| 13 | shiftArithmetic | thrpt | 1 | 5 | 10.358305 | 0.292978 | ops/us | 8 | 1030 |
| 13 | shiftArithmeticUnsafe | thrpt | 1 | 5 | 15.628798 | 0.415542 | ops/us | 0 | 250 |
| 13 | shiftArithmeticUnsafe | thrpt | 1 | 5 | 17.272456 | 0.631146 | ops/us | 0 | 256 |
| 13 | shiftArithmeticUnsafe | thrpt | 1 | 5 | 14.438353 | 0.315382 | ops/us | 0 | 262 |
| 13 | shiftArithmeticUnsafe | thrpt | 1 | 5 | 4.415769 | 0.079505 | ops/us | 0 | 1018 |
| 13 | shiftArithmeticUnsafe | thrpt | 1 | 5 | 4.461373 | 0.080921 | ops/us | 0 | 1024 |
| 13 | shiftArithmeticUnsafe | thrpt | 1 | 5 | 4.132034 | 0.250692 | ops/us | 0 | 1030 |
| 13 | shiftArithmeticUnsafe | thrpt | 1 | 5 | 16.992797 | 0.253043 | ops/us | 1 | 250 |
| 13 | shiftArithmeticUnsafe | thrpt | 1 | 5 | 17.342952 | 0.238273 | ops/us | 1 | 256 |
| 13 | shiftArithmeticUnsafe | thrpt | 1 | 5 | 14.627287 | 0.552194 | ops/us | 1 | 262 |
| 13 | shiftArithmeticUnsafe | thrpt | 1 | 5 | 4.517435 | 0.151964 | ops/us | 1 | 1018 |
| 13 | shiftArithmeticUnsafe | thrpt | 1 | 5 | 4.476616 | 0.054379 | ops/us | 1 | 1024 |
| 13 | shiftArithmeticUnsafe | thrpt | 1 | 5 | 4.153728 | 0.068590 | ops/us | 1 | 1030 |
| 13 | shiftArithmeticUnsafe | thrpt | 1 | 5 | 16.935670 | 0.515578 | ops/us | 7 | 250 |
| 13 | shiftArithmeticUnsafe | thrpt | 1 | 5 | 17.668635 | 0.343247 | ops/us | 7 | 256 |
| 13 | shiftArithmeticUnsafe | thrpt | 1 | 5 | 14.408205 | 0.368361 | ops/us | 7 | 262 |
| 13 | shiftArithmeticUnsafe | thrpt | 1 | 5 | 4.436654 | 0.020834 | ops/us | 7 | 1018 |
| 13 | shiftArithmeticUnsafe | thrpt | 1 | 5 | 4.476475 | 0.039526 | ops/us | 7 | 1024 |
| 13 | shiftArithmeticUnsafe | thrpt | 1 | 5 | 4.172609 | 0.061469 | ops/us | 7 | 1030 |
| 13 | shiftArithmeticUnsafe | thrpt | 1 | 5 | 16.987466 | 0.202447 | ops/us | 8 | 250 |
| 13 | shiftArithmeticUnsafe | thrpt | 1 | 5 | 17.403420 | 0.208813 | ops/us | 8 | 256 |
| 13 | shiftArithmeticUnsafe | thrpt | 1 | 5 | 14.464275 | 0.160839 | ops/us | 8 | 262 |
| 13 | shiftArithmeticUnsafe | thrpt | 1 | 5 | 4.443708 | 0.070989 | ops/us | 8 | 1018 |
| 13 | shiftArithmeticUnsafe | thrpt | 1 | 5 | 4.720626 | 0.171716 | ops/us | 8 | 1024 |
| 13 | shiftArithmeticUnsafe | thrpt | 1 | 5 | 4.253040 | 0.088258 | ops/us | 8 | 1030 |
SWARはJavaではあまり利用されていない技術です。Unsafeを使わず、様々なコンパイラの最適化を放棄することなく、SWARを活用できるといいのですが。Project PanamaのVector APIで実験したとき、最も興味深かった機能は、異なる幅の整数型間で簡単に変換できる機能です。これは特に8ビットの論理右シフトに関連しています。なぜならこの機能はAVX2には存在せず、このエントリの序盤のperfasmの出力で見られるように、いくつかの演算から組み上げる必要があるからです。時間が経てばAVX2はだんだん関連性が薄れていくでしょうし、ベンチマークで使っているコンピュータでそれにアクセスしても、AVX2が重要になることはありませんが、AVX-512はまだそれほど普及しておらず、AMD のサポートもありません。直近でVector APIと戯れていたとき、Wojciech Mula によって考案されたvector bit count algorithmで論理右シフトする場合に、SWAR実行機能があるとパフォーマンス上有益であることがわかりました。
[vector] AVX2 ByteVector.shiftR performance and semantics
https://mail.openjdk.java.net/pipermail/panama-dev/2019-January/004042.html
Faster Population Counts Using AVX2 Instructions
https://arxiv.org/pdf/1611.07612.pdf
Wojciech Mula
https://twitter.com/pshufb
再解釈は最新バージョンのAPIで第1級の概念としてを表現されています。最新バージョンのAPIではSWARのトリックをshiftRightIntで確認できますが、より簡単なshiftRIghtByteでは確認できません。ちなみに、shiftRightByteはJDK13 の自動ベクトル化された符号なしシフトと同様のコードにコンパイルされます。
もちろん、一般性の損失という犠牲はありますが、32バイトでの演算とより高速な8個のint配列に対する演算の間で、2019年1月に遡って10倍のパフォーマンス差がありました。
@Benchmark
public int shiftRightByte() {
return LongVector.fromArray(L256, data, 0)
.reinterpretAsBytes()
.lanewise(LSHR, 4)
.and((byte)0x0F)
.lane(0);
}
@Benchmark
public int shiftRightInt() {
return LongVector.fromArray(L256, data, 0)
.reinterpretAsInts()
.lanewise(LSHR, 4)
.and(0x0F0F0F0F)
.reinterpretAsBytes()
.lane(0);
}
Vector APIが利用可能になる前に、汎用的な方法があるといいですね。
コードはgithubにあります。
JDK13 benchmark
https://github.com/richardstartin/simdbenchmarks/blob/master/src/main/java/com/openkappa/simd/byteshift/ByteShiftBenchmark.java
Vector API benchmark
https://github.com/richardstartin/vectorbenchmarks
